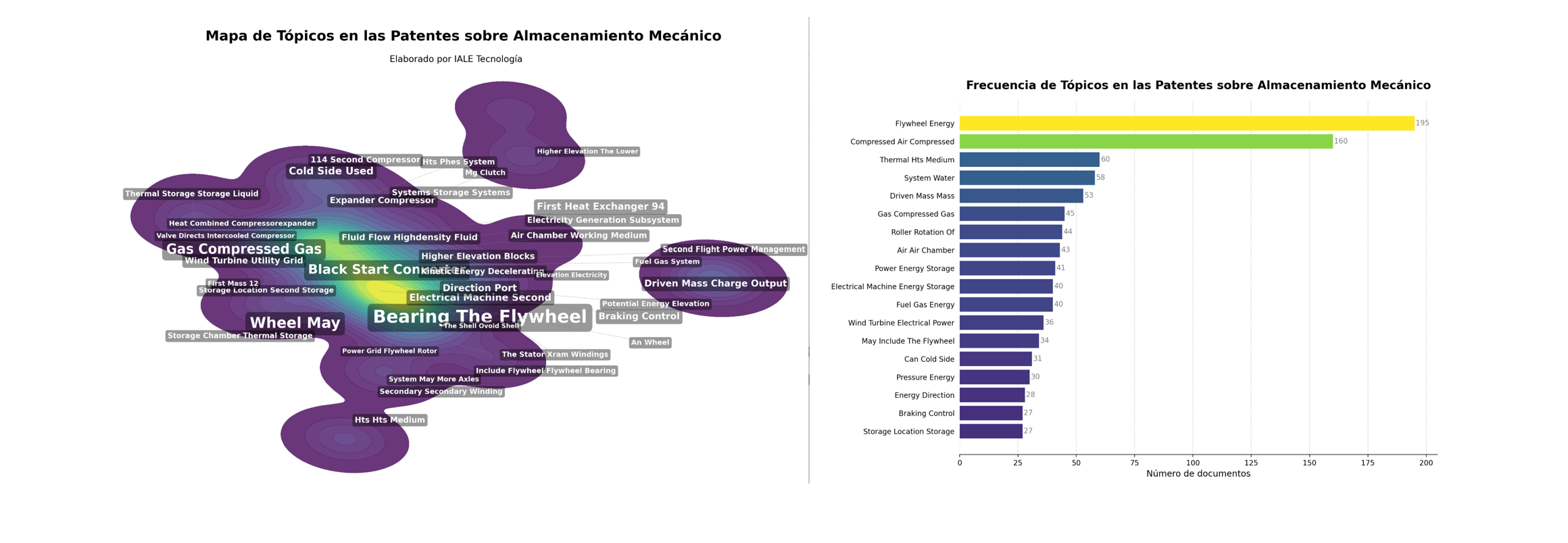
En este pot introducimos el concepto de modelado de temas o Topic Modeling, que es una de las técnicas que utilizamos en IALE en nuestros procesos de minería de datos y textos, para analizar grandes volúmenes de publicaciones u otros tipos de registros documentales que contengan datos textuales.
El modelado de temas o tópicos permite descubrir patrones ocultos en grandes conjuntos de datos textuales, facilitando la organización y comprensión de la información. A través de esta técnica, es posible identificar los temas recurrentes en los datos que estudiamos sin necesidad de etiquetado previo, lo que optimiza el análisis y la extracción de conocimiento
Una de las técnicas de modelado de tópicos más avanzada en la actualidad es BERTopic. BERTopic utiliza modelos de lenguaje basados en arquitectura de redes neuronales (transformers) para descubrir temas en una colección de textos. A diferencia de enfoques más antiguos como LDA, que tratan los documentos como bolsas de palabras (bag of words, los cuales simplemente hacen un recuento de frecuencia de palabras sin tener en cuenta su orden, sintaxi o gramática), BERTopic trabaja con el significado del texto.
Para aplicar una técnica de modelado de tópicos mediante Bertopic, llevamos a cabo los siguientes pasos:
1. Convertimos documentos a vectores (embeddings)
Primero convertimos cada documento en un vector numérico denso (embedding) utilizando un modelo de transformación de oraciones (como all-MiniLM-L6-v2). Así, los documentos con significado similar terminan convertidos en vectores que se encuentran cerca unos de otros en un espacio de alta dimensión.
2. Reducción de dimensionalidad
Estas incrustaciones o embeddings pueden tener cientos de dimensiones, lo cual es demasiado para agruparlas de manera eficiente, así que para reducir esta dimensionalidad aplicamos la técnica conocida como UMAP (Uniform Manifold Approximation and Projection) que básicamente las comprime a un espacio de menor dimensión (por defecto 5D para agrupamiento, 2D para visualización) preservando la estructura de vecindad (es decir, los documentos que eran similares antes siguen estando cerca unos de otros después de la reducción).
3. Clusterización
Utilizamos seguidamente HDBSCAN, que es un algoritmo de clusterización que nos sirve para encontrar agrupaciones naturales en ese espacio reducido. Un aspecto interesante de este algoritmo es que no requiere que le especifiquemos el número de temas por adelantado, sino que los descubre a partir de la propia densidad de los datos (los documentos que no encajan bien en ningún clúster se asignan al tema -1, el tema atípico u outlier).
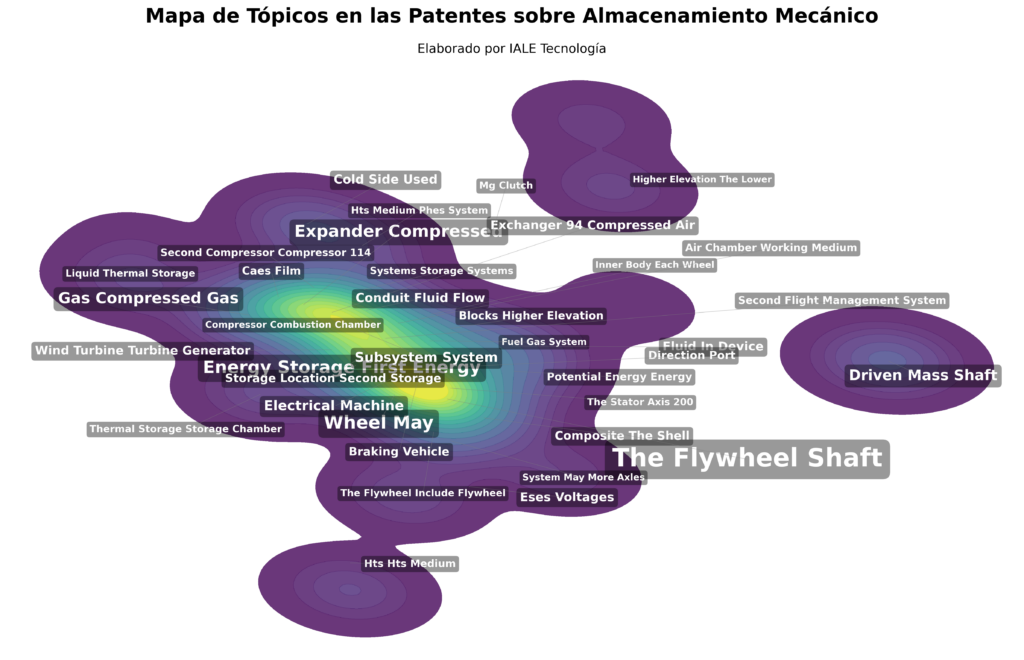
4. Representación y etiquetado de temas
Una vez formados los clústeres, BERTopic necesita una etiqueta para cada uno. Para ello utilizamos una versión modificada de la métrica Term Frequency/Inverse Term Frequency (TF-IDF) llamada c-TF-IDF, que trata todos los documentos de un clúster como un único documento grande y con una fórmula de ponderación del peso relativo, encuentra las palabras más distintivas de ese clúster en comparación con los demás. Como último ajuste, con la ayuda el algoritmo MMR (MaximalMarginalRelevance) finalmente se pueden procesar las palabras clave c-TF-IDF originales para equilibrar la relevancia con la diversidad; así, en lugar de obtener cinco sinónimos cercanos como etiqueta de cada tema, se obtienen palabras que aportan algo diferente, más únicas y distintivas.

En definitiva, los algoritmos de modelado de temas son muy útiles en investigación ya que nos facilitan el análisis y la agrupación automática de grandes volúmenes de texto. BERTopic aprovecha la potencia de los Modelos de Lenguaje, para identificar significados implícitos, temas relevantes y tendencias en datos no estructurados, permitiendo a los investigadores explorar y resumir información textual de manera eficiente, mejorar su comprensión del conjunto estudiado y agilizar la toma de decisiones basada en datos.
Deja una respuesta